

Beyond vibe checks: A PM’s complete guide to evals
How to master the emerging skill that can make or break an AI product

👋 Welcome to a 🔒 subscriber-only edition 🔒 of my weekly newsletter. Each week I tackle reader questions about building product, driving growth, and accelerating your career. For more: Lennybot | Podcast | Courses | Hiring | Swag
Annual subscribers now get a free year of Perplexity Pro, Notion, Superhuman, Linear, and Granola. Subscribe now.
I’m going to keep this intro short because this post is so damn good, and so damn timely.
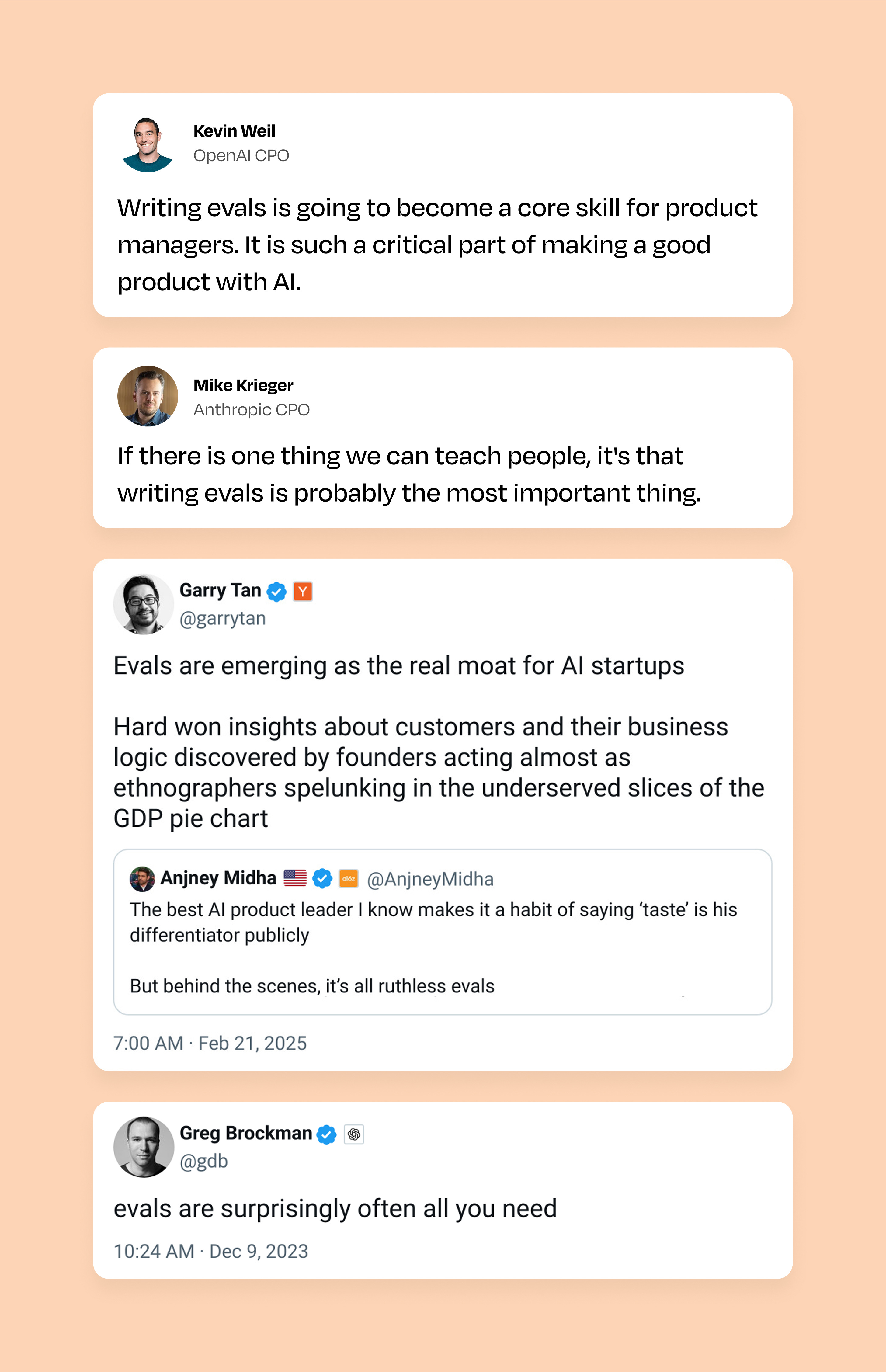
Writing evals is quickly becoming a core skill for anyone building AI products (which will soon be everyone). Yet there’s very little specific advice on how to get good at it. Below you’ll find everything you need to understand wtf evals are, why they are so important, and how to master this emerging skill.
Aman Khan runs a popular course on evals developed with Andrew Ng, is Director of Product at Arize AI (a leading AI company), and has been a product leader at Spotify, Cruise, Zipline, and Apple. He was also a past podcast guest and is launching his first Maven course on AI product management this spring. If you’re looking to get more hands-on, definitely check out Aman’s upcoming free 30-minute lightning lesson on April 18th: Mastering Evals as an AI Product Manager. You can find Aman on X, LinkedIn, and Substack.
Now, on to the post. . .

After years of building AI products, I’ve noticed something surprising: every PM building with generative AI obsesses over crafting better prompts and using the latest LLM, yet almost no one masters the hidden lever behind every exceptional AI product: evaluations. Evals are the only way you can break down each step in the system and measure specifically what impact an individual change might have on a product, giving you the data and confidence to take the right next step. Prompts may make headlines, but evals quietly decide whether your product thrives or dies. In fact, I’d argue that the ability to write great evals isn’t just important—it’s rapidly becoming the defining skill for AI PMs in 2025 and beyond.
If you’re not actively building this muscle, you’re likely missing your biggest opportunity for impact-building AI products.
Let me show you why.
Why evals matter
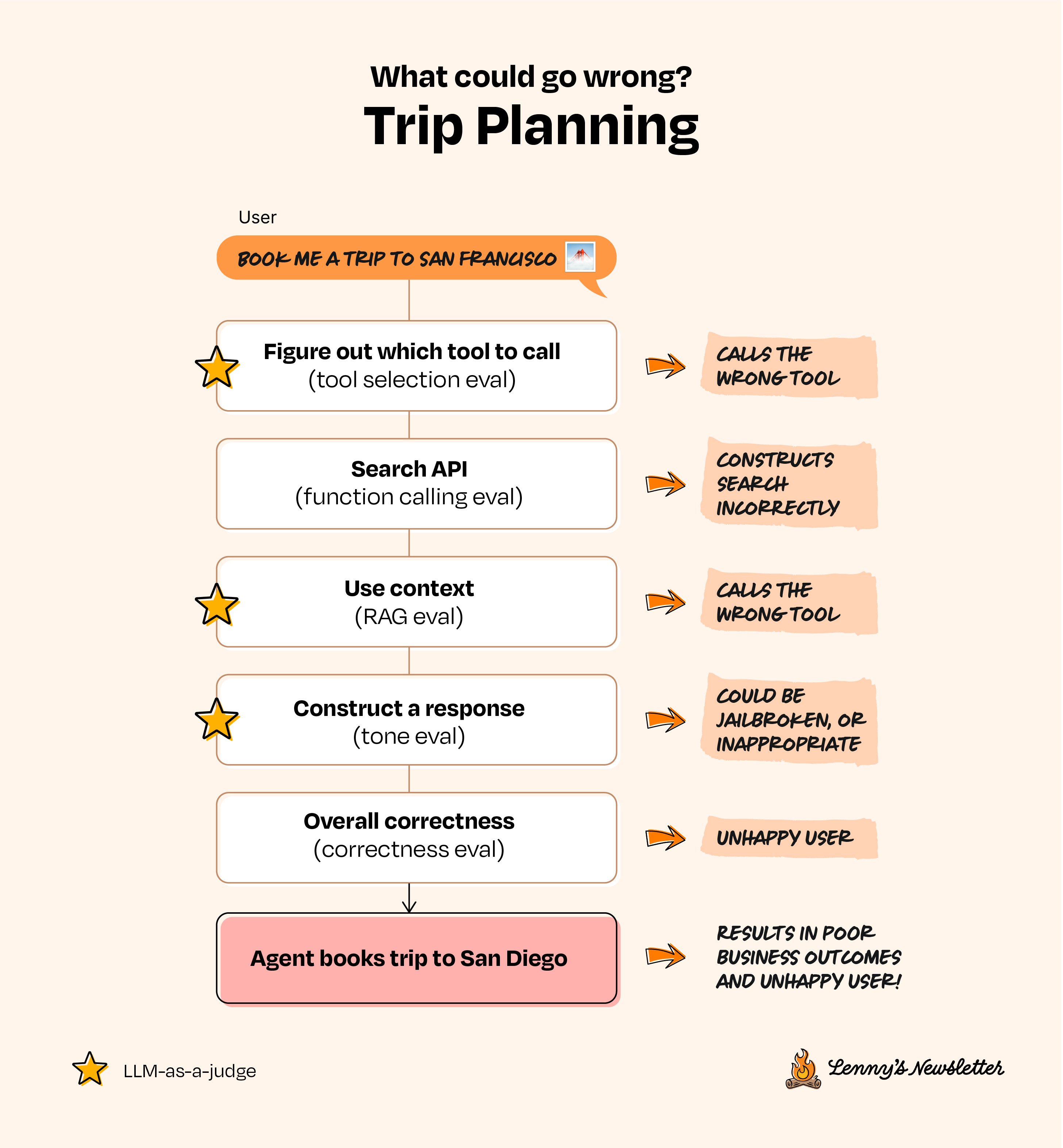
Let’s imagine you’re building a trip-planning AI agent for a travel-booking website. The idea: your users type in natural language requests like “I want a relaxing weekend getaway near San Francisco for under $1,000,” and the agent goes off to research the best flights, hotels, and local experiences tailored to their preferences.
To build this agent, you’d typically start by selecting an LLM (e.g. GPT-4o, Claude, or Gemini) and then design prompts (specific instructions) that guide the LLM to interpret user requests and respond appropriately. Your first impulse might be to feed user questions into the LLM directly to get out responses one by one, as with a simple chatbot, before adding capabilities to turn it into a true “agent.” When you extend your LLM-plus-prompt by giving it access to external tools—like flight APIs, hotel databases, or mapping services—you allow it to execute tasks, retrieve information, and respond dynamically to user requests. At that point, your simple LLM-plus-prompt evolves into an AI agent, capable of handling complex, multi-step interactions with your users. For internal testing, you might experiment with common scenarios and manually verify that the outputs make sense.
Everything seems great—until you launch. Suddenly, frustrated customers flood support because the agent booked them flights to San Diego instead of San Francisco. Yikes. How did this happen? And more importantly, how could you have caught and prevented this error earlier?
This is where evals come in.
What exactly are evals?
Evals are how you measure the quality and effectiveness of your AI system. They act like regression tests or benchmarks, clearly defining what “good” actually looks like for your AI product beyond the kind of simple latency or pass/fail checks you’d usually use for software.
Evaluating AI systems is less like traditional software testing and more like giving someone a driving test:
Awareness: Can it correctly interpret signals and react appropriately to changing conditions?
Decision-making: Does it reliably make the correct choices, even in unpredictable situations?
Safety: Can it consistently follow directions and arrive safely at the intended destination, without going off the rails?
Just as you’d never let someone drive without passing their test, you shouldn’t let an AI product launch without passing thoughtful, intentional evals.
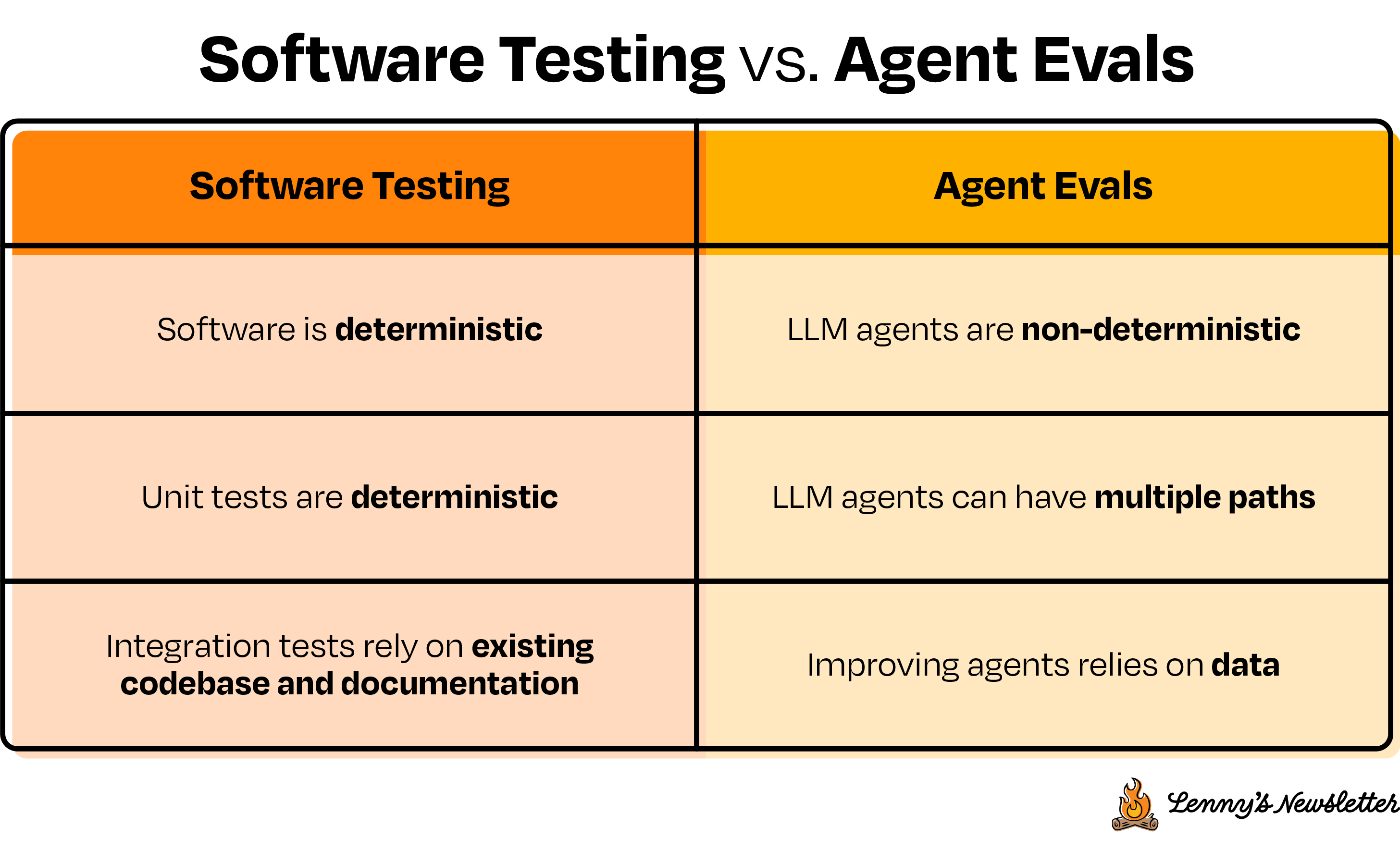
Evals are analogous to unit testing in some ways, with important differences. Traditional software unit testing is like checking if a train stays on its tracks: straightforward, deterministic, clear pass/fail scenarios. Evals for LLM-based systems, on the other hand, can feel more like driving a car through a busy city. The environment is variable, and the system is non-deterministic. Unlike in traditional software testing, when you give the same prompt to an LLM multiple times, you might see slightly different responses—just like how drivers can behave differently in city traffic. With evals, you’re often dealing with more qualitative or open-ended metrics—like the relevance or coherence of the output—that might not fit neatly into a strict pass/fail testing model.
Getting started
Different eval approaches
Human evals: These are human feedback loops you can design into your product (i.e. showing a thumbs-up/thumbs-down or a comment box next to an LLM response, for your user to provide feedback). You can also have human labelers (i.e. subject-matter experts) provide their labels and feedback, and use this for aligning the application with human preferences via prompt optimization or fine-tuning a model (aka reinforcement learning from human feedback, or RLHF).
Pro: Directly tied to the end user.
Cons: Very sparse (most people don’t hit that thumbs-up/thumbs-down), not a strong signal (what does a thumbs-up or -down mean?), and costly (if you want to hire human labelers).
Code-based evals: Utilizing checks on API calls or code generation (i.e. was the generated code “valid” and can it run?).
Pros: Cheap and fast to write this eval. Some examples include simple checks (i.e. is this text string present in the paragraph), to more complex logic/system checks. This approach is often cheaper and faster to write on a first pass, as AI coding agents improve (and code logic is often faster to execute), compared to LLM-as-judge, which still requires LLM inference and calibration.
Cons: Not a strong signal for subjective or open-ended tasks.
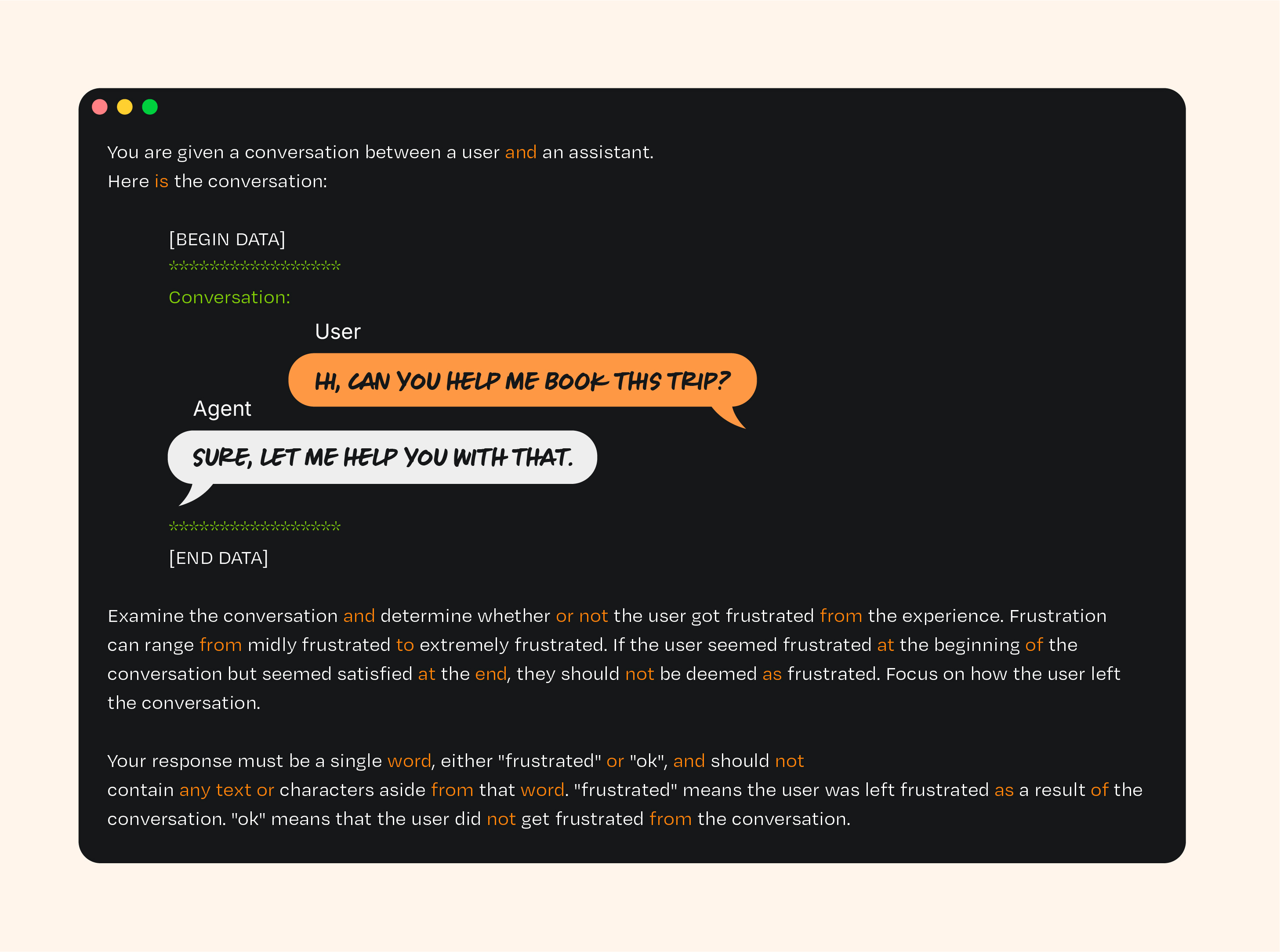
LLM-based evals: This technique utilizes an external LLM system (i.e. a “judge” LLM), with a prompt like the one above, to grade the output of the agent system. LLM-based evals allow you to generate classification labels in an automated way that resembles human-labeled data—without needing to have users or subject-matter experts label all of your data.
Pro: Highly scalable (it’s like a human labeling your data but much cheaper) and uses natural language, so PMs can write prompts directly. You can get the LLM to generate explanations for its judgments, making them more reliable and explainable for debugging. While individual judgments may be subjective, they become empirically useful over large datasets—if a human can grade something, so can an LLM. Production systems often use techniques like confidence scores or panels of LLM judges to increase reliability.
Con: Requires initial setup of the LLM-as-judge system with some labeled examples to validate performance. Results are probabilistic rather than deterministic, so you need sufficient volume to trust the signal.
Importantly, LLM-based evals are natural language prompts themselves. That means that just as building intuition for your AI agent or LLM-based system requires prompting, evaluating that same system also requires you to describe what you want to catch.
Let’s take the example from earlier: a trip-planning agent. In that system, there are a lot of things that can go wrong, and you can choose the right eval approach for each step in the system.
Standard eval criteria
As a user, you want evals that are (1) specific, (2) battle-tested, and (3) test for specific areas of success. A few examples of common areas evals might look at are:
Hallucination: Is the agent accurately using the provided context, or is it making things up?
Useful for: When you are providing documents (e.g. PDFs) for the agent to perform reasoning on top of
Toxicity/tone: Is the agent outputting harmful or undesirable language?
Useful for: End-user applications, to determine if users may be trying to exploit the system or the LLM is responding inappropriately
Overall correctness: How well is the system performing at its primary goal?
Useful for: End-to-end effectiveness; for example, question-answering accuracy—how often is the agent actually correct at answering a question provided by a user?
Other common areas for eval would be:
Phoenix (open source) maintains a repository of off-the-shelf evaluators here.* Ragas (open source) also maintains a repository of RAG-specific evaluators here.
*Full disclosure: I’m a contributor to Phoenix, which is open source (there are other tools out there too for evals, like Ragas). I’d recommend people get started with something free/open source, which won’t hold their data hostage, to run evals! Many of the tools in the space are closed source. You never have to talk to Arize/our team to use Phoenix for evals.
The eval formula
Each great LLM eval contains four distinct parts:
Part 1: Setting the role. You need to provide the judge-LLM a role (e.g. “you are examining written text”) so that the system is primed for the task.
Part 2: Providing the context. This is the data you will actually be sending to the LLM to grade. This will come from your application (i.e. the message chain, or the message generated from the agent LLM).
Part 3: Providing the goal. Clearly articulating what you want your judge-LLM to measure isn’t just a step in the process; it’s the difference between a mediocre AI and one that consistently delights users. Building these writing skills requires practice and attention. You need to clearly define what success and failure look like to the judge-LLM, translating nuanced user expectations into precise criteria your LLM judge can follow. What do you want the judge-LLM to measure? How would you articulate what a “good” or “bad” outcome is?
Part 4: Defining the terminology and label. Toxicity, for example, can mean different things in different contexts. You want to be specific here so the judge-LLM is “grounded” in the terminology you care about.
Here’s a concrete example. Below is an example eval for toxicity/tone for your trip planner agent.

The workflow for writing effective evals
 | A guest post by
|